An uplifting story
In the beginning there was a railway. It grew up to become a network.
Then we got the data. But the data sat on paper. Then in computer files. Lots of files that describe one and the same railway network.
Yet, the data in the files lived their separate lives, grew older and then grew apart.
This is the beginning of a beautiful story in which the data become as linked as the railway network that they describe.
First UK railway Linked Data
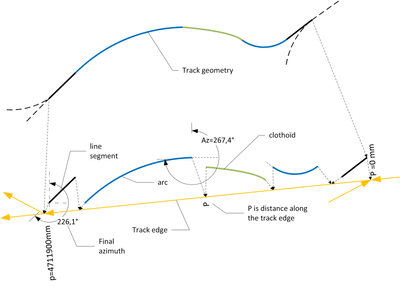
The story begins with a survey of a railway line in the United Kingdom. This survey produced a dataset of classified features and geometries in AXIOM JSON format.
Said features are collected, interpreted and classified in sets of features like so
"type" : "FeatureCollection",
"name" : "SIGNAL",
"features" : [
{
"type" : "Feature",
"geometry" : {
"type" : "Point",
"coordinates" : [ -0.5382930806, 51.5077831311 ]
},
"properties" : {
"SIGNAL_ID" : "6030000000631",
"SIGNAL_IDENTIFIER" : "T6264",
"SUPPORT_STRUCTURE_TYPE" : "Ground",
"VISIBLE_SIGNALS" : null,
"SIGNAL_TYPE" : null,
"ELR" : "MLN1",
"Track_ID" : "1200",
"Ellipse_Asset_Number" : null,
"Ellipse_Asset_Description_1" : null,
"Ellipse_EGI_Description" : null,
"Ellipse_Signal_Code" : null,
"Ellipse_Equip_Status" : null,
"GEOM_SOURCE" : null,
"INFO_SOURCE" : null,
"NOTES" : null,
"CONFIDENCE" : "4",
"Date_of_capture" : "20210309",
"Editor" : "XXX",
"Type_of_capture" : "New", ...
}
},
The challenge - creating EDP Linked Data
- What does a EULYNX DP data model look like in terms of Linked Data ?
- Can this JSON information be cast onto a Linked Dataset that matches the EULYNX Data Prep model ?
The types of features in this file are
- BRIDGE
- NUMBERED_PLATFORM_USABLE_EXTENT
- PHYSICAL_PLATFORM_EXTENT
- PLATFORM_LIMITING_ASSET_GEOMETRY
- PLATFORM_SURFACE_EXTENT
- SANDC_POINT
- SANDC_UNIT
- SIGNAL
- SIGNAL_BLOCK
- SIGNAL_DIRECTION
- STATION_PLATFORM
- TRACK_CENTRELINE
- TRACK_CIRCUIT
- VEHICLE_ARREST_DEVICE
The ETL process is typically carried out by IT-savvy persons. Interpretation of jargon, or more respectfully, domain-specific concepts, like "SANDC" is the first problem that a non-signalling person faces. Finding the corresponding classes in the EDP model is the next challenge. Short, the IT person doing the ETL needs to pick the brains of domain experts, a typical hurdle when prising open silos.
Extract - Transform - Load
The steps to lift the data out of the JSON technology space, mapping the information onto Linked Data are
- identify the features
- find the corresponding EDP classes
- write the mapping rules in RML
- produce RML
Tooling
W3C provides the R2RML language, designed to map Relational databases to RDF triples. We use the [RML](http://rml.io] language, an extension of R2RML that is designed to map data from logical sources to RDF. As opposed to R2RML, The logical sources cover not only RDB but also files such as CSV, JSON, XML. The R2RML and RML languages are declarative, that is, it declares the mapping rules. This is generally considered superior to a imperative approach in which one writes the algorithms, i.e. a sequence of execution instructions. Declarative languages express the intent and bother less with the nitty gritty of how things are stored.
Brief outline of the RML mapping rules
RML declares the rules to map information picked in the logical source to target RDF triples. Of course, the rules are described as triples that may be stored in a turtle file or in a triple store. The rules describe where to lift and where to drop data. The logical source is a façade to the RDB or file holding the source data to be lifted. In our case the source would be
<#signaljson> a rml:logicalSource;
rml:source "/path/to/file.json" ;
rml:referenceFormulation ql:JSONPath;
rml:iterator "$.features[*]" .
This says that the data source is a JSON file, to be queried using JSONpath and that the records are found by iterating over the "features" in the (geo-)JSON file.
The rules that map the source data to triples are represented by a set of triple maps. The triple maps select the subject and predicate to object definition like so:
<#rsmsignal> a rr:TriplesMap;
rml:logicalSource <#signaljson> ;
rr:subjectMap [ rr:class rsm:Signal; rr:template "http://nr.co.uk/rdf/signal/{.properties.SIGNAL_ID}" ];
[
rr:predicate rsm:name;
rr:objectMap [ rml:reference ".properties.SIGNAL_IDENTIFIER" ] ],
[
rr:predicate rsm:locations;
rr:objectMap [ rr:template "http://nr.co.uk/rdf/spotlocations/{.properties.SIGNAL_ID}"; rr:termType rr:IRI ]
] .
The `subjectMap states that every occurence of /feature/properties/SIGNAL_ID (quasi JSON-path) maps to triple subject of type rsm:Signal. This mapping asserts below triple statement:
<http://nr.co.uk/rdf/signal/6030000000631> a rsm:Signal .
The IRI <http://nr.co.uk/rdf/signal/6030000000631> makes the signal findable on the web. The choice of paths suggests that NR will have a store of RDF triples that contains signals. The definition of the signal is found at the location rsm:Signal where rsm is short for <http://ontorail.org/src/RSM/rsm12/.
The two predicateObjectMaps assert the triples:
<http://nr.co.uk/rdf/signal/6030000000631> rsm:name "T6264".
<http://nr.co.uk/rdf/signal/6030000000631> rsm:locations <http://nr.co.uk/rdf/spotlocations/6030000000631>.
Matching the EULYNX Data Prep model
Creating instance data out of JSON is possible using RML declarative rules.
Another question remains open: does this data match the EDP model ?
Unlike XSD technology space, Linked Data doesn't support the notion of schemata. Instead, it is feasible to check that the things such signals, are what they say they are. After all, a signal called S4711 that states that it is a Signal as defined in the namespace http://dataprep.eulynx.eu should look like a Signal as promised by the definition. This implies checking that a signal obeys the logical rules that reside in the defining ontology.
There's more between heaven and earth than the schema
And whilst we're at it, why not define rules that go beyond what a schema such as XSD can do ? For instance, one may want to check that a signal is anywhere close to a railway track. or that it can display meaningful information. There are many rules that are currently stored in documents (and in expert minds) that can be applied to kit that is defined as Linked Data.
That sounds very exciting - how does one create and apply such rules ??
This is where SHACL comes in, and a subject of the next story...